加载本地内容
本指南展示了如何使用 InterceptUrlRequestCallback 从本地目录加载内容。
前提条件
要完成本教程,您将需要:
- Git。
- Java 17 或更高版本。
- 有效的 JxBrowser 许可证。可以是评估版或商业版。有关许可证的更多信息,请参阅许可指南。
创建项目
本教程示例应用程序的代码与其他示例一起,存储在一个基于 Gradle 的 GitHub 仓库中。
如果您想构建一个基于 Maven 的项目,请参考 Maven 配置指南。如果您希望从头开始构建一个基于 Gradle 的项目,请参考 Gradle 配置指南。
获取代码
要获取代码,请执行以下命令:
$ git clone https://github.com/TeamDev-IP/JxBrowser-Examples
$ cd JxBrowser-Examples/tutorials/serve-from-directory
添加许可证
要运行本教程,您需要设置许可证密钥。
您将构建什么
在本教程中,您将创建一个小型应用程序,当浏览器加载特定 URL 时,从本地目录中提供文件。
与启动 HTTP 服务器不同,您将:
- 拦截针对自定义 URL(例如
https://mydomain.com)的 HTTP 请求。 - 将请求的路径映射到本地目录中的某个文件。
- 读取该文件并将其作为 HTTP 响应返回。
实现基础拦截器
拦截单个域名的请求
您将使用 JxBrowser 提供的 URL 请求拦截机制。拦截器实现 InterceptUrlRequestCallback 接口,并针对每个发出的请求被调用,从而可以选择用自定义响应替换默认的网络行为。
首先,创建一个基础拦截器:
import com.teamdev.jxbrowser.net.callback.InterceptUrlRequestCallback;
...
abstract class DomainContentInterceptor implements InterceptUrlRequestCallback {
private final String domain;
DomainContentInterceptor(String domain) {
this.domain = domain;
}
@Override
public Response on(Params params) {
// 在这里处理请求。
// 目前先允许请求通过网络正常处理。
return Response.proceed();
}
/**
* 将请求的 {@code path} 解析为文件并打开。
*/
protected abstract InputStream openContent(String path) throws IOException;
}
这个骨架类声明了基础拦截器类,保存了域名信息,并定义了 openContent(String) 方法,子类将使用该方法提供响应体内容。
接下来,更新 on(Params params) 方法,使其按域名过滤请求:
@Override
public Response on(Params params) {
var uri = URI.create(params.urlRequest().url());
if (!uri.getHost().equals(domain)) {
// 对于其他域名,让 Chromium 像往常一样处理请求。
return Response.proceed();
}
// 在这里处理发往 mydomain.com 的请求。
return Response.proceed();
}
接下来,添加逻辑,通过抽象的 openContent(String) 方法读取内容,并将其作为 HTTP 响应返回。现在我们假设内容总是存在:
import com.teamdev.jxbrowser.net.UrlRequestJob;
import static com.teamdev.jxbrowser.net.HttpStatus.OK;
...
@Override
public Response on(Params params) {
...
// 跳过开头的斜杠。
var path = uri.getPath().substring(1);
try (var content = openContent(path)) {
var job = createJob(params, OK);
writeToJob(content, job);
job.complete();
return Response.intercept(job);
} catch (Exception e) {
// 目前让 Chromium 像往常一样处理此请求。
return Response.proceed();
}
}
/**
* 创建用于构建响应的 `UrlRequestJob` 对象。
*/
private UrlRequestJob createJob(Params params, HttpStatus status) {
var options = UrlRequestJob.Options.newBuilder(status).build();
return params.newUrlRequestJob(options);
}
/**
* 将输入流的内容写入 HTTP 响应中。
*/
private void writeToJob(InputStream stream, UrlRequestJob job)
throws IOException {
var content = stream.readAllBytes();
job.write(content);
}
到目前为止,DomainContentInterceptor 已经可以决定拦截哪些请求、读取实际文件,并将文件内容写入 HTTP 响应。
createJob 方法创建带有给定状态码的响应任务,而 writeToJob 方法负责将内容写入响应。在本教程中,我们在同一个线程中写入响应内容。在真实应用中,您可以在其他线程中异步调用 job.write(...) 和 job.complete(...)。
在下一节中,我们将添加 Content-Type 头,让浏览器知道如何展示内容。
添加 Content-Type 头
为了发送正确的 Content-Type 头,引入一个小型工具类,用于根据文件扩展名推断 MIME 类型,并在构建 HTTP 响应时使用它:
class MimeTypes {
private static final Properties MIME_TYPES = loadMimeTypes();
/**
* 根据 {@code fileName} 的扩展名推导 {@code String} 类型的 MIME。
*/
static String mimeType(String fileName) {
var dotIndex = fileName.lastIndexOf('.');
if (dotIndex < 0 || dotIndex == fileName.length() - 1) {
return "application/octet-stream";
}
var extension = fileName.substring(dotIndex + 1).toLowerCase();
return MIME_TYPES.getProperty(extension, "application/octet-stream");
}
private static Properties loadMimeTypes() {
var properties = new Properties();
var url = MimeTypes.class.getClassLoader().getResource("mime-types.properties");
try (var stream = url.openStream()) {
properties.load(stream);
} catch (IOException ignore) {
// Fall back to the default type.
}
return properties;
}
}
MimeTypes 类使用一个预先填充好的属性文件,用于将扩展名映射到对应的 MIME 类型:
html=text/html
css=text/css
png=image/png
...
接下来,在拦截器中使用这个工具类,使每个响应都包含正确的 Content-Type 头:
import com.teamdev.jxbrowser.net.HttpHeader;
...
@Override
public Response on(Params params) {
...
var path = uri.getPath().substring(1);
try (var content = openContent(path)) {
var mimeType = MimeTypes.mimeType(path);
var contentType = HttpHeader.of("Content-Type", mimeType);
var job = createJob(params, OK, contentType);
writeToJob(content, job);
job.complete();
return Response.intercept(job);
} catch (Exception e) {
// 目前让 Chromium 像往常一样处理此请求。
return Response.proceed();
}
}
private UrlRequestJob createJob(Params params, HttpStatus status, HttpHeader... headers) {
var options = UrlRequestJob.Options.newBuilder(status);
for (var header : headers) {
options.addHttpHeader(header);
}
return params.newUrlRequestJob(options.build());
}
处理缺失的内容
添加缺失内容的处理逻辑,当请求的路径没有可提供的内容时,拦截器应返回 404 Not Found 响应:
import static com.teamdev.jxbrowser.net.HttpStatus.NOT_FOUND;
...
@Override
public Response on(Params params) {
...
var path = uri.getPath().substring(1);
try (var content = openContent(path)) {
if (content == null) {
var job = createJob(params, NOT_FOUND);
job.complete();
return Response.intercept(job);
}
var mimeType = MimeTypes.mimeType(path);
var contentType = HttpHeader.of("Content-Type", mimeType);
var job = createJob(params, OK, singletonList(contentType));
writeToJob(content, job);
job.complete();
return Response.intercept(job);
} catch (Exception e) {
// 目前让 Chromium 像往常一样处理此请求。
return Response.proceed();
}
}
处理读取失败
最后,为读取失败添加错误处理逻辑,使拦截器在读取文件失败时返回 500 Internal Server Error 响应:
import static com.teamdev.jxbrowser.net.HttpStatus.INTERNAL_SERVER_ERROR;
...
@Override
public Response on(Params params) {
...
var path = uri.getPath().substring(1);
try (var content = openContent(path)) {
// ...
} catch (Exception e) {
// 当读取文件失败时返回 500 响应。
var job = createJob(params, INTERNAL_SERVER_ERROR);
job.complete();
return Response.intercept(job);
}
}
实现基于目录的拦截器
现在基础拦截器已经处理了 HTTP 相关的细节,您可以实现一个具体的拦截器,用于从磁盘上的某个目录加载文件。
将 URL 映射到磁盘上的文件
扩展 DomainContentInterceptor,提供一个实现,将请求路径解析到内容根目录,并为存在的文件返回输入流:
import static java.nio.file.Files.exists;
import static java.nio.file.Files.isDirectory;
...
/**
* 从目录中加载文件的拦截器。
*/
class DomainToFolderInterceptor extends DomainContentInterceptor {
private final Path contentRoot;
public DomainToFolderInterceptor(String domain, Path contentRoot) {
super(domain);
this.contentRoot = contentRoot;
}
/**
* 将请求路径解析到文件并打开。
*/
@Override
protected InputStream openContent(String path) throws IOException {
var filePath = contentRoot.resolve(path);
if (exists(filePath) && !isDirectory(filePath)) {
return new FileInputStream(filePath.toFile());
}
return null;
}
}
在这里,openContent(String path) 会:
- 在配置好的目录下解析请求路径。
- 检查文件是否存在并且不是目录。
- 当文件可读取时返回文件流,否则返回
null,基础拦截器会将其转换为404 Not Found响应。
替代方案:从资源中提供内容
在某些情况下,您可能希望提供打包在应用程序 JAR 中的文件,而不是从文件系统读取。
DomainToResourceInterceptor 类遵循与 DomainToFolderInterceptor 相同的模式,但使用类加载器而不是文件系统:
/**
* 从资源中加载文件的拦截器。
*/
class DomainToResourceInterceptor extends DomainContentInterceptor {
private final String resourceRoot;
DomainToResourceInterceptor(String domain, String resourceRoot) {
super(domain);
this.resourceRoot = resourceRoot;
}
@Override
protected InputStream openContent(String path) {
var resourcePath = toResourcePath(path);
return getClass().getClassLoader().getResourceAsStream(resourcePath);
}
private String toResourcePath(String path) {
var normalized = path.startsWith("/") ? path.substring(1) : path;
if (resourceRoot.isEmpty()) {
return normalized;
}
if (resourceRoot.endsWith("/")) {
return resourceRoot + normalized;
}
return resourceRoot + "/" + normalized;
}
}
这里的 resourceRoot 指向类路径上打包静态资源的文件夹。其余行为与前一种方式相同:基础拦截器使用返回的输入流构建 HTTP 响应并推导 Content-Type 头。
拦截器的实际使用
最后一步是创建一个 Engine 实例、注册拦截器,并加载映射到本地目录的 URL。
注册拦截器
在应用程序入口中,创建拦截器并为 https:// 协议注册它:
import static com.teamdev.jxbrowser.engine.RenderingMode.HARDWARE_ACCELERATED;
import com.teamdev.jxbrowser.browser.Browser;
import com.teamdev.jxbrowser.engine.Engine;
import com.teamdev.jxbrowser.engine.EngineOptions;
import com.teamdev.jxbrowser.net.Scheme;
import java.nio.file.Path;
import java.nio.file.Paths;
public final class Application {
public static void main(String[] args) {
var contentRoot = Paths.get("content-root");
var interceptor =
DomainToFolderInterceptor.create("mydomain.com", contentRoot);
var options =
EngineOptions.newBuilder(HARDWARE_ACCELERATED)
.licenseKey("your license goes here")
.addScheme(Scheme.HTTPS, interceptor)
.build();
var engine = Engine.newInstance(options);
var browser = engine.newBrowser();
// ...
}
}
打开 URL
创建一个带有 BrowserView 的 Swing 窗口,并加载指向本地内容的 URL:
import com.teamdev.jxbrowser.view.swing.BrowserView;
...
public final class Application {
public static void main(String[] args) {
// ...
var browser = engine.newBrowser();
invokeLater(() -> {
var view = BrowserView.newInstance(browser);
var frame = new JFrame("Serve files from disk");
frame.setDefaultCloseOperation(WindowConstants.EXIT_ON_CLOSE);
frame.add(view, BorderLayout.CENTER);
frame.setSize(1280, 720);
frame.setLocationRelativeTo(null);
frame.setVisible(true);
});
browser.navigation().loadUrl("https://mydomain.com/index.html");
}
}
运行此应用程序时,Browser 将加载 https://mydomain.com/index.html。拦截器会捕获该请求,在配置的目录下解析 index.html,并直接从本地文件系统提供该文件。
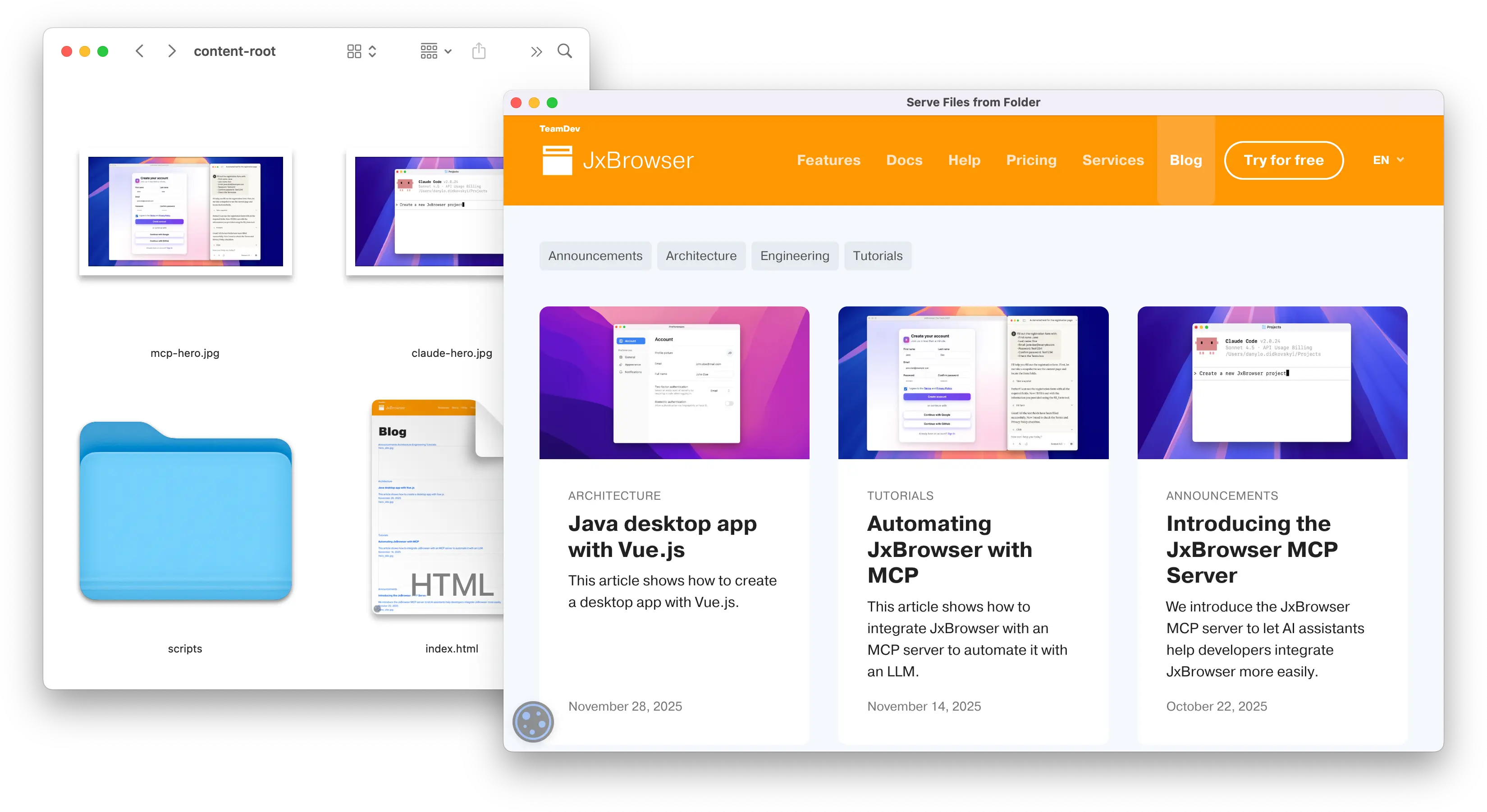
使用请求拦截器从本地文件夹提供内容的网页。