
如今,互联网上充斥着海量的数据。为了满足市场调研和商业决策的需求,我们经常需要提取和分析这些数据。当需要时,这些工作必须得到高效执行,以确保决策的准确性和及时性。
为什么需要收集和分析数据?这可能是出于多种原因:
- 进行网站审计;
- 汇总在线商店的数据;
- 为神经网络准备训练集;
- 监控社交媒体、新闻源、博客上的评论;
- 分析网站内容,如识别网站上的失效链接等。
这些数据并不局限于文本,它可以是图片、视频、表格、各种文件等。在处理这些数据时,我们可能需要提取链接和文本信息,通过关键词或短语进行搜索,或者收集相关图片等。
另一个至关重要的任务是监控网站的健康状况,检查是否存在失效链接,以及网站是否普遍可用。
而所有这些工作,都需要借助现成的工具来完成。
现有解决方案
收集和分析数据最常见的方法是向 Web 服务器发送请求,接收返回的 HTML 响应,并对其进行处理。在此过程中,我们需要解析 HTML 来提取必要信息。
然而,现代网页广泛使用 JavaScript,许多页面的内容都是动态加载或生成的。仅仅从 Web 服务器获取响应是不够的 — 因为响应可能只是一个包含大量 JavaScript 的引导页面,只有在执行这些 JavaScript 脚本之后才会生成所需的内容。
如何利用 Web 浏览器的功能?
网站是为人创建的,人们通过 Web 浏览器访问网站。
利用 Web 浏览器来收集数据到底有何优势呢?相较于仅通过向 Web 服务器发送请求的传统方式,这种方法能够规避许多限制和约束。特别是对于那些需要登录并在页面上执行一系列复杂操作才能获取结果的网站,浏览器的方式更为适用。此外,通过控制浏览器的用户代理(User-Agent),我们能够更灵活地模拟不同用户的访问行为,从而避免被服务器识别为机器人。同时,这也有助于我们接收面向桌面的内容,而不仅仅是针对移动设备的简化版本。
在本文中,我们将探讨使用 Web 浏览器功能收集数据的方法。具体来说,我们将收集指定网站上的所有链接,并检查其中是否存在任何损坏链接,即因任何原因而无法访问的页面链接。我们将通过 JxBrowser 库利用 Chromium 浏览器的功能来实现这一目标。
JxBrowser 是一款商业 Java 库,它能够让商业 Java 应用程序充分利用 Chromium 的强大功能。对于使用 Java 技术开发和销售软件解决方案的公司,或者需要为内部需求创建的 Java 应用程序配备高级且可靠的 Web 浏览器组件的公司来说,它非常实用。
开始前我们应该做些什么?
在开始设计解决方案和编写代码之前,我们需要考虑哪些要点?我们需要从网站的某个特定页面开始。这可以是一个主页或者一个网址。
在该页面上,我们应该找到指向其他页面的链接。链接可能指向其他网站(外部链接)和同一网站的其他页面(内部链接)。此外,链接并不总是指向另一个页面。有些链接会将访问者带到同一页面的某个部分(这类链接通常以 # 开头)。有些链接并不是真正的链接,而是发送电子邮件的快捷方式 — mailto:。
由于链接可能是循环的,所以我们需要特别小心。为了正确处理循环引用,我们需要记住已经访问过的页面。
此外,检查链接指向的页面是否无法访问也至关重要,最好能够获得一个错误代码,以解释为什么无法访问该页面。
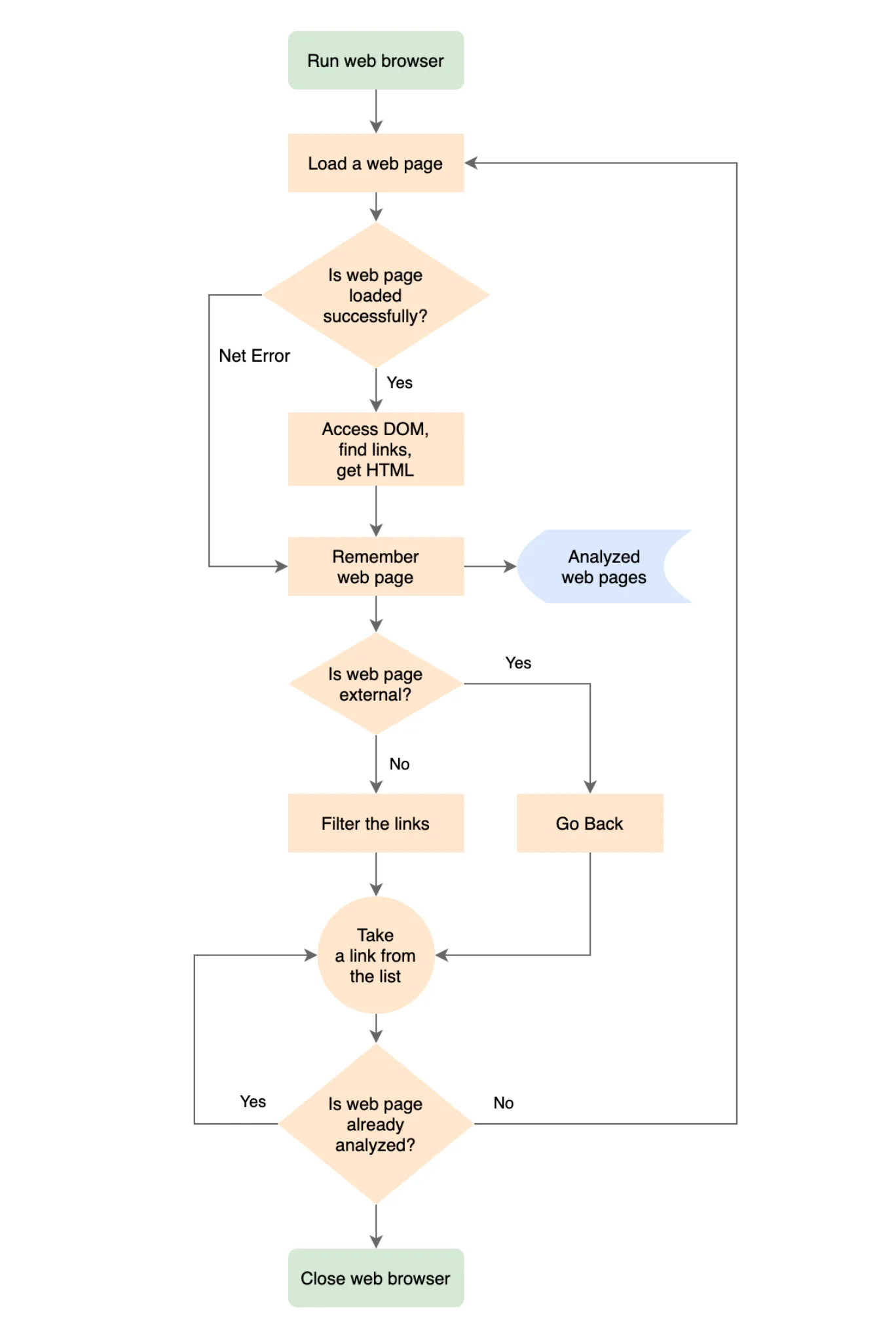
算法
基于上述所有信息,让我们试着思考一个基于浏览器的程序将如何工作。
- 启动 Web 浏览器。
- 加载所需的网页。
- 如果页面已加载,则访问其 DOM 并查找所有锚点 HTML 元素。对于每个锚点元素,获取其每个组件的 HREF 值。这样,我们将获得页面上的所有链接。
- 如果页面未加载,则记住该页面 Web 服务器的错误。
- 记住已处理的页面。
- 如果页面属于我们的网站,则过滤链接;移除那些我们不感兴趣的链接,比如指向页面子部分或 mailto: 的链接。
- 遍历收到的链接列表。
- 对于列表中的每个页面,按照步骤从第 1 步开始执行。
- 如果它是外部页面,则将其记住,但不必对其链接进行分析。我们仅关注我们网站页面上的链接。
- 处理完所有发现的页面后,完成导航。
- 关闭 Web 浏览器。
- 遍历所有分析过的页面,并找出其中包含损坏链接的页面。
以下是以流程图形式呈现的程序算法。
实现
让我们看看如何实现这些主要阶段。
启动 Web 浏览器:
Engine engine = Engine.newInstance(OFF_SCREEN);
Browser browser = engine.newBrowser();
加载网页:
browser.navigation().loadUrlAndWait(url, Duration.ofSeconds(30));
获取 DOM 访问权限并搜索链接:
browser.mainFrame().flatMap(Frame::document).ifPresent(document ->
// 通过分析锚点 HTML 元素的 HREF 属性来收集链接。
document.findElementsByTagName("a").forEach(element -> {
try {
String href = element.attributeValue("href");
toUrl(href, browser.url()).ifPresent(
url -> result.add(Link.of(url)));
} catch (IllegalStateException ignore) {
// 网页的 DOM 可能会被 JavaScript 动态更改。
// 我们分析的 DOM HTML 元素可能在我们的分析过程中被移除。
// 我们不分析已移除 DOM 元素的属性。
}
}));
获取 HTML 页面:
/**
* 返回表示当前已加载网页 HTML 的字符串。
*/
private String html(Browser browser) {
AtomicReference<String> htmlRef = new AtomicReference<>("");
browser.mainFrame().ifPresent(frame ->
htmlRef.set(frame.html()));
return htmlRef.get();
}
分析网站的主类示例。
package com.teamdev.jxbrowser.examples.webcrawler;
import static com.google.common.base.Preconditions.checkNotNull;
import static com.teamdev.jxbrowser.engine.RenderingMode.OFF_SCREEN;
import com.google.common.collect.ImmutableSet;
import com.teamdev.jxbrowser.browser.Browser;
import com.teamdev.jxbrowser.engine.Engine;
import com.teamdev.jxbrowser.engine.EngineOptions;
import java.io.Closeable;
import java.util.HashSet;
import java.util.Optional;
import java.util.Set;
/**
* 基于 JxBrowser 的网页爬虫实现,
* 可以发现和分析网页,
* 访问它们的 DOM 和 HTML 内容,
* 查找网页上的损坏链接等。
*/
public final class WebCrawler implements Closeable {
/**
*
* 为给定的目标 {@code url} 创建一个新的 {@code WebCrawler} 实例。
*
* @param url 爬虫将开始分析的目标网页的 URL
* @param factory 用于为内部和外部 URL 创建 {@link
* WebPage} 实例的工厂
*/
public static WebCrawler newInstance(String url,
WebPageFactory factory) {
return new WebCrawler(url, factory);
}
private final Engine engine;
private final Browser browser;
private final String targetUrl;
private final Set<WebPage> pages;
private final WebPageFactory pageFactory;
private WebCrawler(String url, WebPageFactory factory) {
checkNotNull(url);
checkNotNull(factory);
targetUrl = url;
pageFactory = factory;
pages = new HashSet<>();
engine = Engine.newInstance(
EngineOptions.newBuilder(OFF_SCREEN)
// 在 Chromium 的隐身模式下访问网页。
.enableIncognito()
.build());
browser = engine.newBrowser();
}
/**
* 启动网络爬虫,并通过给定的 {@code listener} 报告进度。
* 分析网站所需的时间取决于发现的网页数量。
*
* <p>此操作会阻塞当前线程的执行,
* 直到爬虫停止分析已发现的网页。
*
* @param listener 一个监听器,将被调用来报告进度。
*/
public void start(WebCrawlerListener listener) {
checkNotNull(listener);
analyze(targetUrl, pageFactory, listener);
}
private void analyze(String url, WebPageFactory factory,
WebCrawlerListener listener) {
if (!isVisited(url)) {
WebPage webPage = factory.create(browser, url);
pages.add(webPage);
// 通知监听器已访问了一个网页。
listener.webPageVisited(webPage);
// 如果是外部网页,则不遍历其链接。
if (url.startsWith(targetUrl)) {
webPage.links().forEach(
link -> analyze(link.url(), factory,
listener));
}
}
}
/**
* 检查给定的 {@code url} 是否属于已访问过的网页。
*/
private boolean isVisited(String url) {
checkNotNull(url);
return page(url).orElse(null) != null;
}
/**
* 返回此网络爬虫已分析过的网页的不可变集合。
*/
public ImmutableSet<WebPage> pages() {
return ImmutableSet.copyOf(pages);
}
/**
* 返回一个包含与给定 {@code url} 关联的网页的 {@code Optional},
* 如果不存在这样的网页,
* 则返回空的选项。
*/
public Optional<WebPage> page(String url) {
checkNotNull(url);
for (WebPage page : pages) {
if (page.url().equals(url)) {
return Optional.of(page);
}
}
return Optional.empty();
}
/**
* 释放所有已分配的资源,
* 并关闭用于发现和分析网页的网页浏览器。
*/
@Override
public void close() {
engine.close();
}
}
完整的程序代码可在 GitHub 上获取。
结果
如果我们编译并运行程序,我们应该得到以下输出:
https://teamdev.com/jxbrowser [OK]
https://teamdev.com/about [OK]
https://teamdev.com/jxbrowser/docs/guides/dialogs/ [OK]
https://teamdev.com/jxcapture [OK]
https://teamdev.com/jxbrowser/api/7.13/com/teamdev/jxbrowser/view/javafx/BrowserView.html [OK]
https://spine.io [OK]
https://jxbrowser.support.teamdev.com/support/tickets [OK]
https://sos-software.com [OK]
...
Dead or problematic links:
https://www.teamdev.com/jxbrowser
https://www.shi.com CONNECTION_TIMED_OUT
http://www.comparex-group.com ABORTED
http://www.insight.com NAME_NOT_RESOLVED
https://www.swnetwork.de/swnetwork ADDRESS_UNREACHABLE
...
Process finished with exit code 0
细微差别、问题及解决方案
以下是在各个网站上实施和测试该解决方案期间遇到的一些细微差别。
许多 Web 服务器受到 DDoS 攻击的保护,频繁的请求会被拒绝,并返回错误代码 ABORTED。为了减轻对网站的负载并进行“礼貌的”分析,我们需要使用超时机制。在程序中,我们使用了 500 毫秒的延迟。但不幸的是,即使设置了这样的延迟,Web 服务器仍然会拒绝我们的请求。
我们没有放弃,接着尝试在不同的时间间隔内加载页面:
/**
* 加载给定的 {@code url} 并等待网页完全加载。
*
* 如果网页已成功加载,则 @return {@code true}。
* 如果给定的 URL 无效,或者我们未能在 45 秒内加载它,
* 则返回 {@code false}。
*
* @implNote 在每次导航之前,我们等待 {@link
* #NAVIGATION_DELAY_MS}, 因为网络服务器可能会经常中断 URL 请求,
* 以保护自己免受 DDoS 攻击。
*/
private NetError loadUrlAndWait(Browser browser, String url,
int navigationAttempts) {
// 我们尝试加载给定 URL 的所有尝试都被拒绝了,(
// 我们放弃并继续处理其他网页。
if (navigationAttempts == 0) {
return NetError.ABORTED;
}
try {
// Web 服务器可能经常中断 URL 请求,
// 以保护自身免受 DDoS 攻击。
// 在 URL 请求之间使用延迟。
long timeout = (long) NAVIGATION_DELAY_MS
* navigationAttempts;
TimeUnit.MILLISECONDS.sleep(timeout);
// 加载给定的 URL 并等待网页完全加载。
browser.navigation()
.loadUrlAndWait(url, Duration.ofSeconds(30));
} catch (NavigationException e) {
NetError netError = e.netError();
if (netError == NetError.ABORTED) {
// 如果 Web 服务器中断了我们的请求,请重试。
return loadUrlAndWait(browser, url,
--navigationAttempts);
}
return netError;
} catch (TimeoutException e) {
// Web 服务器在 30 秒内未响应 (
return NetError.CONNECTION_TIMED_OUT;
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
return NetError.OK;
}
Web 服务器在加载页面时可能会执行重定向操作。当我们尝试加载一个地址时,可能会被自动重定向到另一个地址。我们可以记住这两个地址,但重要的是不要只记住应用程序中请求的地址。
Web 服务器可能不会对某些请求做出任何响应。因此,在加载页面时,我们需要使用超时机制来等待下载。如果在这个超时时间内页面仍未加载完成,则应将页面标记为不可用,并返回错误 CONNECTION_TIMED_OUT。
在某些网页上,DOM 模型可能会在页面加载后立即更改。因此,在分析 DOM 模型时,我们必须处理一些 DOM 元素可能不遍历 DOM 树的情况。
browser.mainFrame().flatMap(Frame::document).ifPresent(document ->
// 通过分析锚点 HTML 元素的 HREF 属性来收集链接。
document.findElementsByTagName("a").forEach(element -> {
try {
String href = element.attributeValue("href");
toUrl(href, browser.url()).ifPresent(
url -> result.add(Link.of(url)));
} catch (IllegalStateException ignore) {
// 网页的 DOM 可能会被 JavaScript 动态地更改。
// 我们分析的 DOM HTML 元素,
// 可能会在分析过程中被移除。
// 我们不分析已移除的 DOM 元素的属性。
}
}));
当然,您在分析中可能会遇到许多其他网站的细微差别。但幸运的是,Web 浏览器的强大功能可以帮助您解决其中大多数问题。
结论
您可以使用 Web 浏览器来创建 Java 爬虫,根据我们的经验,这是一种更自然的网站通信方式。在专业软件市场中,许多 SEO 爬虫和网页抓取工具多年来一直在使用这些基于浏览器功能的业务驱动解决方案,充分证明了这种方法的有效性。
您可以进行实验并尝试新的程序转变。从 GitHub 下载源代码,根据您的需求进行编辑。
如果您对此方法有任何疑问,请在下方留言。我将很乐意详细解答您的所有问题。
发送中。。。
您的个人 JxBrowser 试用密钥和快速入门指南将在几分钟内发送至您的电子邮箱。