AI 功能通常依赖云服务。这在许多情况下效果很好,但并不总是必要的。对于某些任务,本地运行模型可能是更好的选择,尤其是在隐私、离线访问或可预测延迟至关重要的情况下。
现代 Web 技术已经使得在本地运行 AI 模型成为可能。浏览器可以下载模型、缓存它,并使用 CPU 或 GPU 执行推理。
许多桌面应用程序使用称为 Web 视图的组件来嵌入浏览器引擎。由于它依赖于与常规浏览器相同的技术,因此它也可以在本地窗口内下载并运行本地 AI 模型。
在本文中,我们将使用 DotNetBrowser 和 Transformers.js 构建一个 .NET 桌面应用程序,该程序直接在用户机器上运行本地 AI 模型。
本地 AI 的适用场景
这种方式最适合那些更贴近用户、且不需要大型模型开销的小型 AI 功能。
它具有一些实际优势:
- 更好的隐私性,因为提示词和输出结果都可以保留在设备本地。
- 在模型资源下载完成后,可以离线或部分离线使用。
- 更低的后端成本,因为应用程序不依赖托管推理服务。
- 对模型选择和特定任务优化有更高的控制力。
它也伴随着一些权衡:
- 浏览器中的本地 AI 通常使用较小的模型,这可能会限制复杂任务的推理能力和准确性。
- 性能高度依赖用户的硬件配置。
- 首次下载体积较大,较大的模型也会占用更多内存。
应用结构
为了演示这种方法,我们将构建一个简单的写作助手。该应用程序允许用户将文本粘贴到文本区域中并进行转换。
它支持三种操作:总结文本、缩短文本或改写文本。用户输入文本并选择操作后,应用程序会将请求发送给本地模型,并在输入框下方显示结果。
在底层,该应用程序依赖三个主要组件:
- Avalonia UI 创建原生桌面外壳并承载嵌入式浏览器。
- DotNetBrowser 在该窗口中嵌入 Chromium Engine 并加载 Web 界面。
- Transformers.js 在嵌入式浏览器页面中运行本地 AI 模型。
下图展示了这些组件如何协同工作:
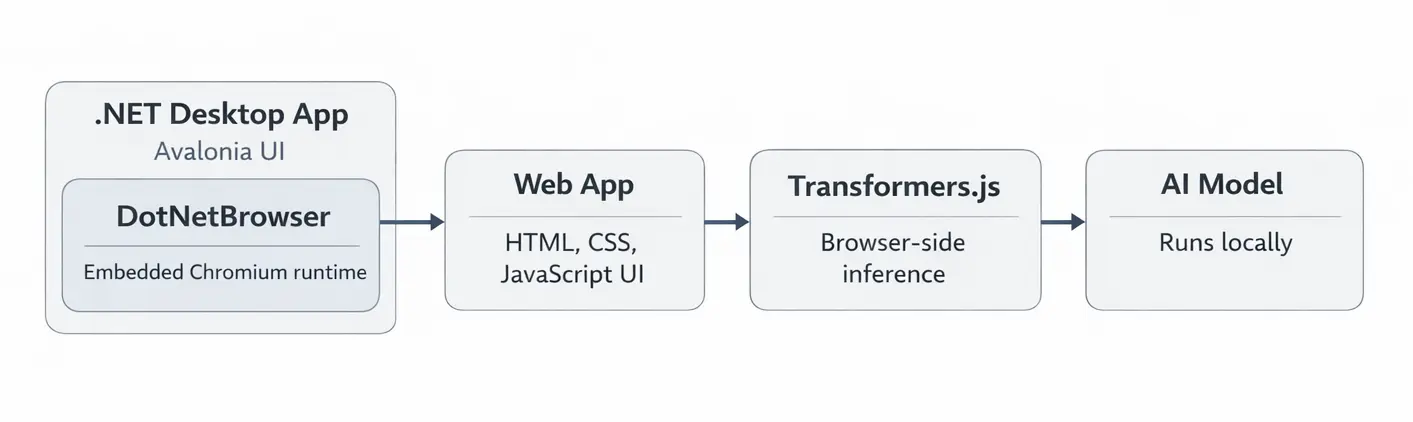
应用程序架构。
设置桌面宿主
我们首先创建一个 .NET 宿主应用程序,用于显示 Web UI。对于桌面外壳,我们使用 Avalonia 创建原生窗口和布局,并通过 DotNetBrowser 将 Web UI 嵌入其中。
为了简化设置,我们可以使用官方的 DotNetBrowser Avalonia 模板。它已经包含了基本项目结构和浏览器初始化代码。
首先,安装模板:
dotnet new install DotNetBrowser.Templates
然后创建一个新项目:
dotnet new dotnetbrowser.avalonia.app -o local-llm-assistant -li <your_license_key>
此命令会创建一个可直接运行的 Avalonia 应用程序。默认情况下,该应用会打开一个窗口,并在 DotNetBrowser 中加载一个网页。
我们将不再加载外部页面,而是将其配置为提供我们自己的 Web UI 和 JavaScript 代码。为此,我们将使用一个自定义 URI 方案,它允许浏览器通过诸如 dnb://app/ 这样的自定义 URL 加载 Web 应用文件。
添加以下 scheme handler 实现:
internal sealed class LocalAppSchemeHandler
: IHandler<InterceptRequestParameters, InterceptRequestResponse>
{
public const string Domain = "dnb://app/";
public static readonly Scheme Scheme = Scheme.Create("dnb");
public InterceptRequestResponse Handle(InterceptRequestParameters parameters)
{
string relativePath = GetRelativePath(parameters.UrlRequest.Url);
string fullPath = Path.Combine(AppContext.BaseDirectory, "web", relativePath);
UrlRequestJob job = parameters.Network.CreateUrlRequestJob(
parameters.UrlRequest,
new UrlRequestJobOptions
{
HttpStatusCode = HttpStatusCode.OK,
Headers = new List<HttpHeader>
{
new HttpHeader("Content-Type", GetMimeType(fullPath).Value)
}
});
job.Write(File.ReadAllBytes(fullPath));
job.Complete();
return InterceptRequestResponse.Intercept(job);
}
}
然后在 MainWindow.axaml.cs 中创建 Engine 时注册该 scheme:
EngineOptions engineOptions = new EngineOptions.Builder
{
LicenseKey = "<your_license_key>",
RenderingMode = RenderingMode.HardwareAccelerated,
Schemes =
{
{ LocalAppSchemeHandler.Scheme, new LocalAppSchemeHandler() }
}
}.Build();
browser.Navigation.LoadUrl(LocalAppSchemeHandler.Domain);
当浏览器加载 dnb://app/ 时,该处理程序会将这个 URL 映射到 web/ 目录中的文件,并返回其内容。这样一来,浏览器就可以从应用程序打包的文件中加载 Web 应用,而无需单独的 Web 服务器。
创建 Web UI
现在我们可以构建 DotNetBrowser 将要加载的 Web UI 了。
创建一个 web/index.html 文件,并添加如下最简页面:
<body>
<main class="app">
<h1>Local Writer Assistant</h1>
<textarea id="input" placeholder="Paste text here"></textarea>
<div class="actions">
<button data-action="summarize">Summarize</button>
<button data-action="shorten">Shorten</button>
<button data-action="rephrase">Rephrase</button>
</div>
<pre id="output">Model output will appear here.</pre>
</main>
<script type="module" src="./app.js"></script>
</body>
这为我们提供了一个输入文本的文本区域、三个操作按钮,以及一个用于显示生成结果的面板。其余浏览器端逻辑将写在 app.js 中。
运行本地模型
Transformers.js 提供了高级的 pipeline() API,用于加载模型并针对特定任务执行推理。在本示例中,我们使用 text2text-generation 任务,它接收输入文本并生成转换后的文本,因此非常适合这个写作助手应用。我们还使用了 Xenova/LaMini-Flan-T5-783M 模型,因为它体积足够小,适合本地运行,同时仍能生成较为合理的结果。
为简化示例,这里使用原生 JavaScript,但同样的方法也适用于任何 Web UI 框架。
创建一个 web/app.js 文件来加载 AI 模型:
import { pipeline } from "https://cdn.jsdelivr.net/npm/@huggingface/transformers@3.8.1";
const MODEL_ID = "Xenova/LaMini-Flan-T5-783M";
async function createGenerator() {
if (navigator.gpu) {
try {
return await pipeline("text2text-generation", MODEL_ID, {
device: "webgpu",
dtype: "q4",
});
} catch (error) {
console.warn("WebGPU initialization failed, falling back.", error);
}
}
return await pipeline("text2text-generation", MODEL_ID, {
dtype: "q4",
});
}
在上面的代码中,我们向 pipeline 传入 device: "webgpu" 以启用 GPU 加速。Transformers.js 使用该选项访问 WebGPU API。这使模型计算可以在 GPU 而不是 CPU 上运行,从而显著提升性能。
DotNetBrowser 在其嵌入式 Chromium Engine 中支持 WebGPU,因此只要系统支持,模型就可以使用 GPU 加速。
将 UI 操作连接到模型
接下来,我们需要将这三种操作与模型连接起来,使每个按钮都能执行不同的文本转换。
在同一个 app.js 文件中,添加以下代码:
const input = document.querySelector("#input");
const output = document.querySelector("#output");
const buttons = document.querySelectorAll("button[data-action]");
const generator = await createGenerator();
const prompts = {
summarize: (text) => `Summarize this text in 3 bullet points: ${text}`,
shorten: (text) => `Shorten this text while preserving the meaning: ${text}`,
rephrase: (text) => `Rephrase this text in clearer language: ${text}`,
};
for (const button of buttons) {
button.addEventListener("click", async () => {
const action = button.dataset.action;
const prompt = prompts[action](input.value.trim());
const result = await generator(prompt, {
max_new_tokens: 128,
temperature: 0.2,
do_sample: false,
});
output.textContent = result[0].generated_text;
});
}
当用户点击按钮时,应用程序会读取输入文本,构建相应的提示词,并将其发送给模型。然后,生成的输出会显示在 UI 中。
运行应用程序
在项目目录下运行:
dotnet run
窗口打开后,将一些文本粘贴到输入框中,然后点击其中一个操作按钮。应用程序会在本地运行模型,并在同一个窗口中显示生成结果。
稍作样式美化后,应用程序效果如下:
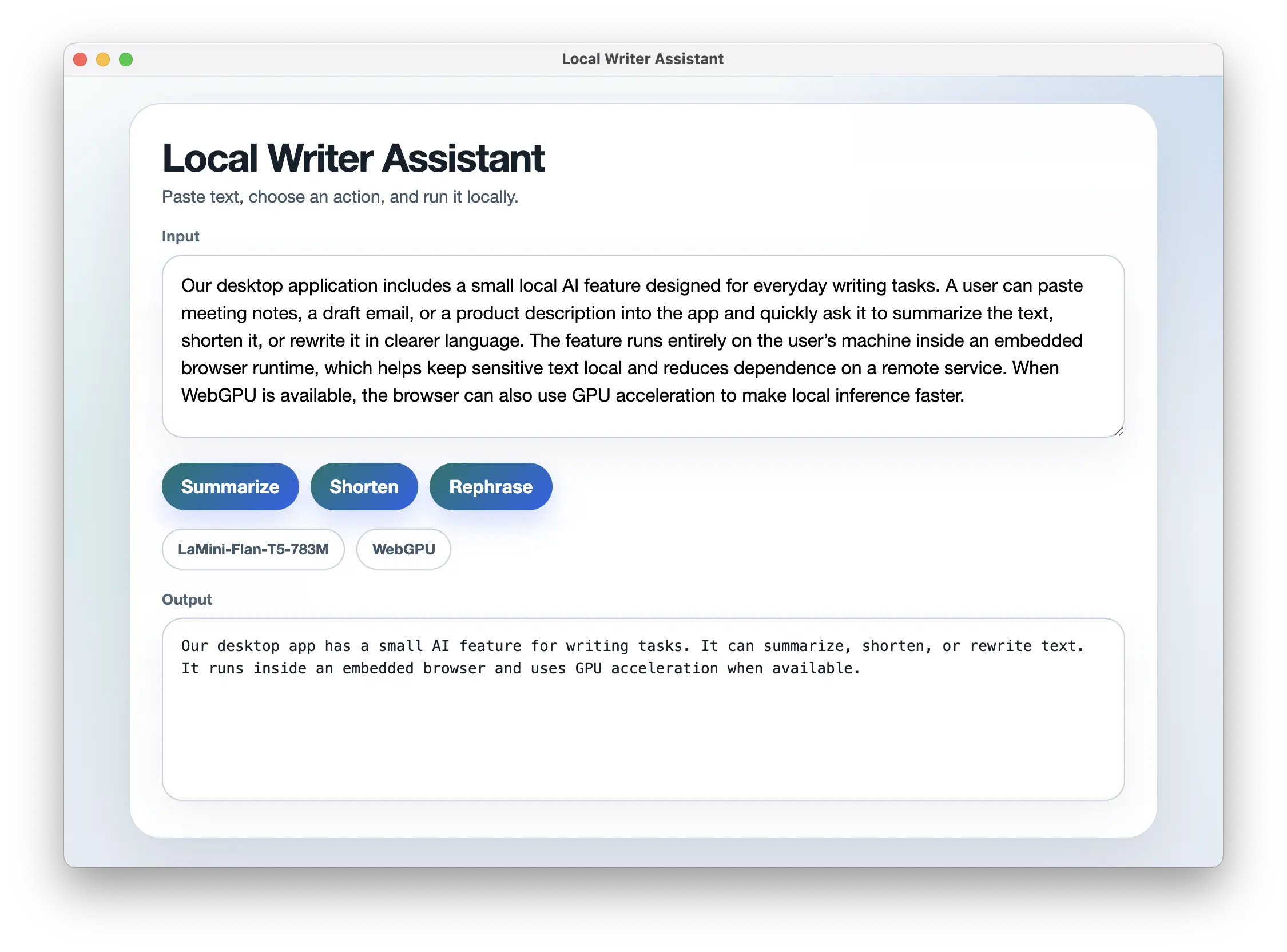
在 .NET 桌面窗口中运行的本地 AI 模型。
你可以在 GitHub 仓库中找到完整示例。
总结
在本教程中,我们使用 Avalonia、DotNetBrowser 和 Transformers.js 构建了一个小型桌面写作助手。该应用程序在 .NET 窗口中加载 Web UI,并使用本地模型对文本进行转换。
当你希望将处理保留在设备本地时,这是一种为桌面应用添加小型 AI 功能的实用方式。对于那些重视隐私、离线访问或可预测响应时间的功能来说,这种方式尤其有用。
发送中。。。
您的个人 DotNetBrowser 试用密钥和快速入门指南将在几分钟内发送至您的电子邮箱。